Pytorchを使用してCNNで画像分類してみましょう。Google Colaboratoryを使用するのでネットさえつながっていれば、どの環境でも再現することができます。
今回は転送学習を使用せずに学習していこうと思います。
CIFAR-10とは?
猫、鳥、飛行機など10種類のラベリングがされた画像データセットです。50000枚のトレーニング画像と10000枚のテスト画像から構成されています。画像サイズは32ピクセルx32ピクセルでRGBのカラー画像です。
Pytorchのデータセットが用意されているので簡単に使用することができます。
前準備
Google Colaboratory を使って実装してみましょう。
ライブラリやGPUの準備
インストール。最近のcolabは事前にPytorchがインストールされているみたいです。
!pip install torch torchvision
%matplotlib inline必要なライブラリをインポートします。pytorchとmatplotlib、そしてCIFAR-10のデータセットを使用するためtorchvisionからdatasetsをインポートしましょう。
import torch
import matplotlib.pyplot as plt
import numpy as np
import torch.nn.functional as F
from torch import nn
from torchvision import datasets, transformsGPUを初期化します。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpt")学習データの準備
pytorchデータを読み込みましょう。データを読み込むときにトランスフォームを定義しています。画像の正規化やリサイズです。トレーニングデータとテストデータで二つ作成しています。トレーニングデータの方はRadomRotationやRandomHorizontalFlipなどを使用してデータオーグメンテーションしています。
最後の行のDataLoaderでバッチサイズを決めています。もし自前のGPUで計算するときはbatch_size=100の数値を変えれば負荷を軽減することができます。
transform_train = transforms.Compose([transforms.Resize((32,32)),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.RandomAffine(0, shear=10, scale=(0.8,1.2)),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5),(0.5, 0.5, 0.5)),
])
transform = transforms.Compose([transforms.Resize((32,32)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5),(0.5, 0.5, 0.5)),
])
training_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
validation_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
training_loader = torch.utils.data.DataLoader(training_dataset, batch_size=100, shuffle=True)
validation_loader = torch.utils.data.DataLoader(validation_dataset, batch_size = 80, shuffle=False)CIFAR-10のデータはそのままではピクセルで表示できないので、ヘルパー関数を定義します。
def im_convert(tensor):
image = tensor.clone().detach().numpy()
image = image.transpose(1,2,0)
image = image * np.array((0.5,0.5,0.5)) + np.array((0.5,0.5,0.5))
image = image.clip(0,1)
return imageデータセットから20個を取り出して表示してみましょう。
dataiter = iter(training_loader)
images, labels = dataiter.next()
fig = plt.figure(figsize=(25, 4))
for idx in np.arange(20):
ax = fig.add_subplot(2, 10, idx+1, xticks=[], yticks=[])
plt.imshow(im_convert(images[idx]))
ax.set_title(classes[labels[idx].item()])


モデル定義
LeNetで学習するつもりなので、LeNetを定義しましょう。畳み込みレイヤーとrelu、maxプーリングの組み合わせなのでコードを見れば簡単にわかると思います。
class LeNet(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 16, 3, 1, padding=1)
self.conv2 = nn.Conv2d(16, 32, 3, 1, padding=1)
self.conv3 = nn.Conv2d(32, 64, 3, 1, padding=1)
self.fc1 = nn.Linear(4*4*64, 500)
self.dropout1 = nn.Dropout(0.5)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
x = F.relu(self.conv3(x))
x = F.max_pool2d(x, 2, 2)
x = x.view(-1, 4*4*64)
x = F.relu(self.fc1(x))
x = self.dropout1(x)
x = self.fc2(x)
return x事deviceをモデルに定義します。
model = LeNet().to(device)損失関数とOptimizer
損失関数は CrossEntropyLoss、OprimizerはAdamを使用します。ラーニングレートは0.001にしています。
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)学習する
学習
学習しましょう。長くなるのでコードの中にコメントで解説しています。エポック数は15にしています。トレーニングデータとテストデータの学習過程をリストで記録しています。これは後でプロットするためです。
epochs = 15
running_loss_history = []
running_corrects_history = []
val_running_loss_history = []
val_running_corrects_history = []
for e in range(epochs):
running_loss = 0.0
running_corrects = 0.0
val_running_loss = 0.0
val_running_corrects = 0.0
for inputs, labels in training_loader:
# DataLoaderのバッチサイズごとにforで取り出して計算
# ここのforの処理が終わると1エポック
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
# 一旦パラメーターの勾配をゼロにして
optimizer.zero_grad()
# 勾配の計算
loss.backward()
# 学習
optimizer.step()
# 分類わけなので、もっとも数字が大きいものをpredictとする
# バッチ処理しているので2次元目で比較
_, preds = torch.max(outputs, 1)
running_loss += loss.item()
# ラベルと合っているものを足し合わせてaccuracy計算
running_corrects += torch.sum(preds == labels.data)
else:
# pytorchでは勾配の計算の高速化のため、パラメーターを保持しているがテスト時はいらないので止める
with torch.no_grad():
for val_inputs, val_labels in validation_loader:
val_inputs = val_inputs.to(device)
val_labels = val_labels.to(device)
val_outputs = model(val_inputs)
val_loss = criterion(val_outputs, val_labels)
_, val_preds = torch.max(val_outputs, 1)
val_running_loss += val_loss.item()
val_running_corrects += torch.sum(val_preds == val_labels.data)
# 学習過程を記録
epoch_loss = running_loss/len(training_loader.dataset)
epoch_acc = running_corrects.float()/ len(training_loader.dataset)
running_loss_history.append(epoch_loss)
running_corrects_history.append(epoch_acc)
val_epoch_loss = val_running_loss/len(validation_loader.dataset)
# print('len-validation_loader :'+str(len(validation_loader)))
# print('len-validation_loader :'+str(len(validation_loader.dataset)))
val_epoch_acc = val_running_corrects.float()/len(validation_loader.dataset)
val_running_loss_history.append(val_epoch_loss)
val_running_corrects_history.append(val_epoch_acc)
print('epoch *', (e+1))
print('training loss: {:.4f}, training acc {:.4f}'.format(epoch_loss, epoch_acc.item()))
print('validation loss: {:.4f}, validation acc{:.4f}'.format(val_epoch_loss,val_epoch_acc.item()))出力結果。すべて書くと長くなるので、最後だけ掲載しています。
epoch * 15
training loss: 0.0071, training acc 0.7534
validation loss: 0.0089, validation acc0.7612正答率は75%ぐらいですね
学習経過をプロットしてみる
記録していたリストを使用して、プロットしてみましょう。
plt.plot(running_loss_history, label='training loss')
plt.plot(val_running_loss_history, label='validation loss')
plt.legend()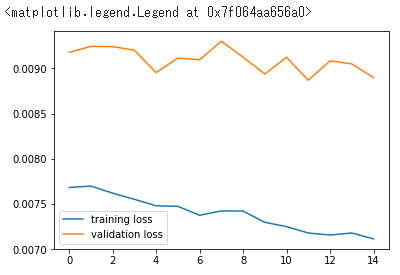
plt.plot(running_corrects_history, label='training accuracy')
plt.plot(val_running_corrects_history, label='validation accuracy')
plt.legend()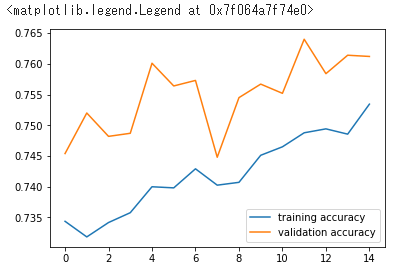
エポック数が少ないので線がガタガタですが、学習が進んでいることがわかると思います。
学習したモデルを使用して画像分類してみる
実際に画像を推測してみましょう
ネットの画像を推測する
ネットから拾った画像を、学習したモデルを使用して画像分類してみましょう。
pillowの最新バージョンに不具合があるのでバージョンを指定しています。
!pip3 install pillow==4.0.0
import PIL.ImageOps鹿を検索してみて出てきた画像を表示してみます。
import requests
from PIL import Image
url = 'http://www.nara-wu.ac.jp/gp2007/gakusei/tenkai/2008/sika_kawa/image/narakouen_01.jpg'
response = requests.get(url, stream=True)
img = Image.open(response.raw)
plt.imshow(img)
そのままでは画像が大きいのでtransformを使用してテスト用のデータセットと同じになるようにします。
img = transform(img)
plt.imshow(im_convert(img))
ではこの画像を学習モデルを使用して推測してみましょう!
image = img.to(device).unsqueeze(0)
output = model(image)
_, pred = torch.max(output, 1)
print(classes[pred.item()])出力結果
deer正しく推測できています。
テストデータを使用して精度を見てみる
テストデータセットから20個を取り出して推測してみます。その結果をプロットしてみましょう。
dataiter = iter(validation_loader)
images_r, labels_r= dataiter.next()
images = images_r.to(device)
labels = labels_r.to(device)
output = model(images)
_, preds = torch.max(output, 1)
fig = plt.figure(figsize=(25, 4))
for idx in np.arange(20):
ax = fig.add_subplot(2, 10, idx+1, xticks=[], yticks=[])
plt.imshow(im_convert(images_r[idx]))
ax.set_title("{} ({})".format(str(classes[preds[idx].item()]), str(classes[labels[idx].item()])), color=("green" if preds[idx]==labels[idx] else "red"))
カエルや犬などが間違っていますが、そこそこ正しく推測できてますね。
まとめ
今回はPytorchを使って一からモデルを作り学習してみました。エポック数やラーニングレートなどのハイパーパラメータを調整して学習すれば、もっと精度は上がります。ですが時間がかかるので転移学習を用いるのが一般的でしょう。
PytorchとGoogle Colaboratoryを使用すれば簡単に画像分類を体験できるので、是非ご自身で実行してみてください。